Scalaのリファクタリング小ネタ (例外)
例外時にデフォルトを取るような場合
// not bad
try { "a".toInt } catch { case e: Throwable => 0 }
// good
Try { "a".toInt }.getOrElse(0)
例外をOptionで取る場合
// not bad
try { Some("a".toInt) } catch { case e: Throwable => None }
// good
Try { "a".toInt }.toOption
// good
allCatch.opt { "a".toInt }
例外をEitherで取る場合
// not bad
try { Right("a".toInt) } catch { case e: Throwable => Left(e) }
// good
allCatch.either { "a".toInt }
Tryで取りたいがfinallyもしたい
// not bad
Try { "a".toInt } match { case t => println("logged"); t }
// good?
allCatch.andFinally { println("logged") }.withTry { "a".toInt }
関係ないけどOptionはIterableになるのか
// OptionにはIterableへのimplicitが定義してある
scala> Option(1).zip(Seq(2))
res14: Iterable[(Int, Int)] = List((1,2))
// こういうことも
scala> for {
| s <- Seq("1", "two", "3")
| i <- Try(s.toInt).toOption
| } yield i
res13: Seq[Int] = List(1, 3)
try-catchよりTryかCatchを使うと大体の場合短く分かりやすく書ける気がする。
パスワードを省略したssh接続
一番いいのは、鍵認証(コマンド限定)。
鍵認証できないのなら、sshpass。(expectはやめよう)
引数から ./sshpass -p “password" ssh root@192.168.1.1 ファイルから echo "password" > pw ./sshpass -f pw ssh root@192.168.1.1 環境変数から export SSHPASS=password ./sshpass -e ssh root@192.168.1.1
./sshpass -p “password" rsync ./fuga.txt root@192.168.1.1:~/
sshpassもレスポンスの文字列を見てるから、基本的にはそうするしかないもよう。
ブランチを新しい順に並べて表示
ブランチを更新日時順に並べるワンライナー。git branch sort by update tim ...
gawkが必要 brew install gawk
gitの便利なfilterまとめ
gitのfilterは、checkout時 と add時 に任意のフィルターをかけることができる。
概念図
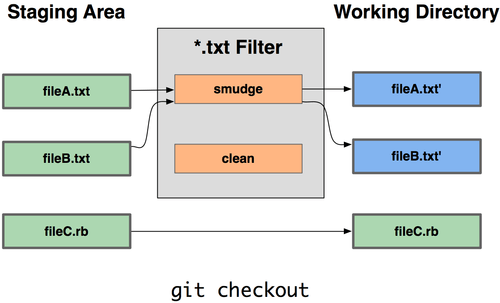
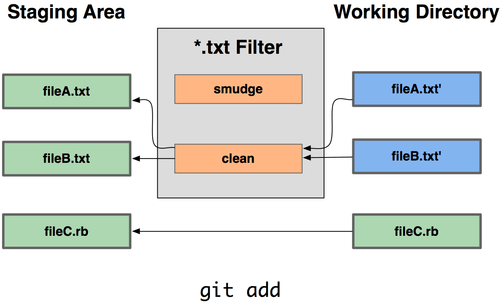
$Gcid$にコミットIDを埋め込むフィルターを作ってみる
やりたいこと
git checkout時に指定ファイルの、
echo "$Gcid$"→echo "$Gcid: bcc4bbe68b26a65a1597752a$"に展開。
git add時は逆に、
echo "$Gcid: bcc4bbe68b26a65a1597752a$"→echo "$Gcid$"に戻す。
手順
- gitの設定でfilterを定義 (.git/config)
- フィルターの対象を定義 (.gitattributes)
- フィルター時に実行するスクリプトを用意 (embed-commit-id.rb)
- フィルターされるファイルを用意 (fuga.sh)
- 試す
. ├─ .git/config (~/.gitconfigでも/etc/gitconfigでも) ├─ .gitattributes ├─ embed-commit-id.rb └─ fuga.sh
1. gitの設定でフィルターを定義 (.git/config)
フィルターの設定をする。
$ vi .gitconfig [filter "embed-commit-id"] smudge = ruby embed-commit-id.rb clean = perl -pe \"s/\\\\\\$Gcid[^\\\\\\$]*\\\\\\$/\\\\\\$Gcid\\\\\\$/\"
2. フィルターの対象を定義 (.gitattributes)
フィルターをかけるファイルを指定する。
$ vi .gitattributes fuga.sh filter=embed-commit-id
3. フィルター時に実行するスクリプトを用意 (embed-commit-id.rb)
smudgeフィルターで実行するスクリプト
$ vi embed-commit-id.rb
#! /usr/bin/env ruby
puts STDIN.read.gsub('$Gcid$', '$Gcid: ' + `git rev-parse HEAD`.strip + '$')
4. フィルターされるファイルを用意 (fuga.sh)
フィルターされるファイルに、変数を埋め込む。
$ vi fuga.sh echo "$Gcid$"
ここで一旦全部コミットしておく
5. 試し
変数は未展開
$ cat fuga.sh echo "$Gcid$"
checkoutする
$ rm fuga.sh $ git checkout fuga.sh
チェックアウトを経由するとフィルターにより展開される
$ cat fuga.sh echo "$Gcid: 3c6c5646726ba5948a9c0198f856bdce0be330de$"
変更してaddしてみる
$ echo "fuga" >> fuga.sh $ git add fuga.sh
addするとフィルターにより変数が元に戻り差分が出ない
$ git diff --cached echo "$Gcid$" +fuga (もちちんcheckoutじゃなくてcloneでも同様の効果が得られる)
まとめ
スタイルチェック通らないとaddできないようにするとか、
任意のスクリプトをcheckout/add時に動かせるので色んなことが出来そう。
Scalaのリファクタリング小ネタ (コレクション)
mapしてflattenするなら、flatMap
// bad
.map { ... }.flatten
// good
.flatMap { ... }
filterしてmapするなら、collect
// bad
.filter { ... }.map { ... }
// good
.collect { ... }
mapしてreverseするなら、reverseMap
// bad
.map { ... }.reverse
// good
.reverseMap { ... }
flatMap内でmapするなら、for
例えば、List[Option[A]]のようなありがちな構造に何かするとき
// not bad..
l.flatMap { o =>
o.map(_ * 2)
}
// good!
for {
o <- l
i <- o
} yield i * 2
さらにfilterを追加してみる
// not bad..
l.flatMap { o =>
o.filter(i => i == 2).map(_ * 2)
}
// good!
for {
o <- l
i <- o if i == 2
} yield i * 2
そもそも内部的にはflatMapに変換される
Listへ要素を追加するときは先頭に (参考表)
末尾への追加やsizeの取得はO(n)かかってしまう。ケースごとに適切なコレクションを使う。 // bad Seq(3, 2) :+ 1 // good 1 +: Seq(2, 3)
map等の中でmatchは省略
// bad
.map { op => op match { case Some(i) => i * i case None => 0 } }
// good
.map { case Some(i) => i * i case None => 0 }
filterしてsizeするならcount
// bad? .filter(_ % 2 == 0).size // good .count(_ % 2 == 0)
タプルの数値アクセスは極力控える
個人的には許したくない。絶対に。
// bad
Seq((1, 2), (3, 4)).map { t => t._1 + ":" + t._2 }
// good
Seq((1, 2), (3, 4)).map { (id, age) => id + ":" + age }
タプルは多くなったらcase classに
// bad type ResultSet = (Int, String, Long) // good case class ResultSet(id: Int, name: String, width: Long)
Option等はコレクションの関数を使う
// bad
Option(1) match {
case Some(1) => true
case _ => false
}
// good
Option(1).exists(_ == 1)
// bad
if (o.isDefined && o.get == "a") Some(o.get * 2) else None
// good
o.collect { case q if q == "a" => q * 2 }
大量の要素を色々するときは、viewを使う
// bad
(0 to 10000000).map { ... }.filter { ... }.scan { ... }
// good
(0 to 10000000).view.map { ... }.filter { ... }.scan { ... }.force
EffectiveScalaは読むべし。